FEMU
1. FEMU NVMe 协议
1.1 数据结构
提交队列 SQ
1 | typedef struct NvmeCmd { |
FUSE:推测可能跟文件系统有关
PRP,SGL:帮助Host告知Controller数据在Host内存中的具体地址
PRP:由PRP1和PRP2表示传输的物理页地址,当传输的物理页无法有两个PRP表示,则PRP可以表示PRP Lists,并且每个指向的物理页的最后一个prp项指向下一个PRP Lists页。
SGL:由于PRP只能表示一个个物理页,SGL能表示起始地址+长度,
完成队列 CQ
1 | typedef struct NvmeCqe { |
1.2 功能函数
创建I/O CQ
1 | uint16_t nvme_create_cq(FemuCtrl *n, NvmeCmd *cmd) |
创建I/O SQ
1 | uint16_t nvme_create_sq(FemuCtrl *n, NvmeCmd *cmd) |
read / write
1 | static uint16_t nvme_rw(FemuCtrl *n, NvmeNamespace *ns, NvmeCmd *cmd, |
命令提交
1 | void nvme_process_sq_io(void *opaque, int index_poller){ |
命令完成
1 | static void nvme_post_cqe(NvmeCQueue *cq, NvmeRequest *req){\ |
1.3 NVMe处理流程
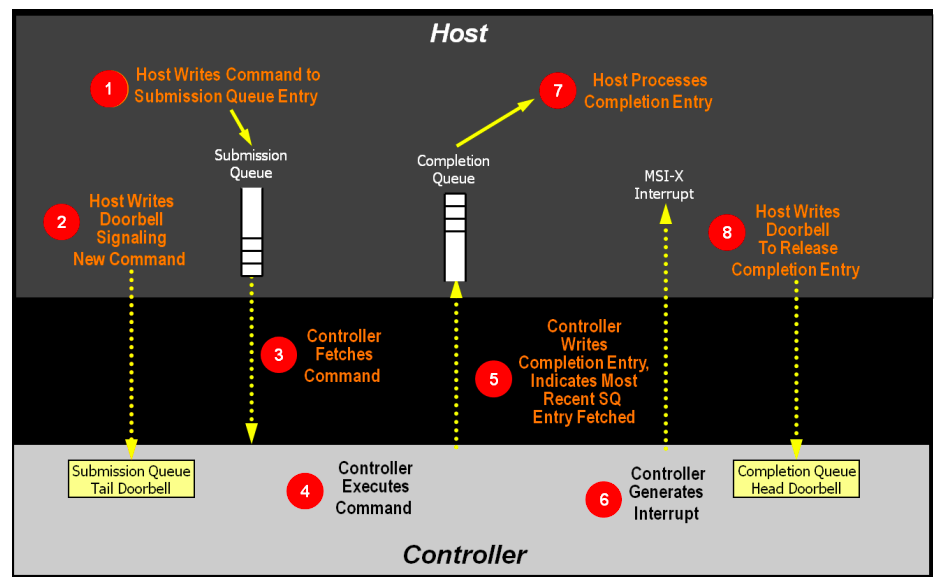
- 主机将一个至多个执行命令放置在内存中下一个空闲提交队列槽位;
- 主机用提交队列尾指针作为新值更新提交队列尾门铃寄存器,告知控制器有一个新的命令被提交,需要处理;
- 控制器将提交队列槽位的命令传输至控制器,这里会用到仲裁机制,决定传输哪一个提交队列的命令;
- 控制器(可能乱序)执行命令;
- 命令执行完成后,控制器将完成队列项放置在与之关联的完成队列的空闲槽位,控制器会移动完成队列项中的提交队列头指针,告知主机最近一次被消耗的提交队列命令, Phase Tag 会被反转,表明完成队列项是新的(这里的理解是,由于完成队列是环形队列,当环形队列由尾部工作至头部时,表明完成一个周期,而 Phase Tag 则表示完成队列项是否完成一个周期);
- 控制器可能会产生中断告知主机有一个新的完成队列项要处理;
- 主机处理完成队列中的完成队列项(过程 A),这里可能会做相应的错误处理,过程 A 持续直至遇到反转的 Phase Tag 终止(主机处理完成队列项会将同一周期内的处理完);
- 主机写完成队列头部门铃寄存器,表明完成队列项已经被处理。
2. FEMU 的数据与逻辑地址分离处理
仿真时,真实数据写入内存,逻辑地址单独处理
nvme_process_sq_io:
1. 生成一个io命令 nvme_io_cmd
2. nvme_rw -> femu_rw_mem_backend_bb写入内存
3. femu_ring_enqueue(n->to_ftl[index_poller], (void *)&req, 1); 取出slba和len传给to_ftl仿真
3. FTL poller的时延仿真
…